
It is not surprising that graphs are being employed by more and more companies, especially the big ones. The ever increasing data volume and complexity is a serious problem, and that is precisely why graph databases were introduced. Bear with me as we learn what a graph database is.
Data models
In order to understand how graph databases operate, we have to first go over the data models a little bit. This knowledge is essential to make a decision whether you will use a graph database in the future.
Relational Model
It is by far the most known data model out there. The data in it is organized into relations (tables) which consist of tuples (rows).
When you look at the schema above you may get an idea that relational model creates a graph of entities, but in reality each foreign key is an ID of an entry in another table with the same primary key. These arrows are there just to make us, humans, understand the data layout easily.
The problem with such solution is that it is not coherent with the way we write our applications. It’s due to the fact that we see the data as nested structures whereas it’s completely flat in a table. In such case an awkward layer between the application and a database has to be introduced. Its sole purpose is to map an object to tabular format and vice versa. This is called Object-Relational Mismatch.
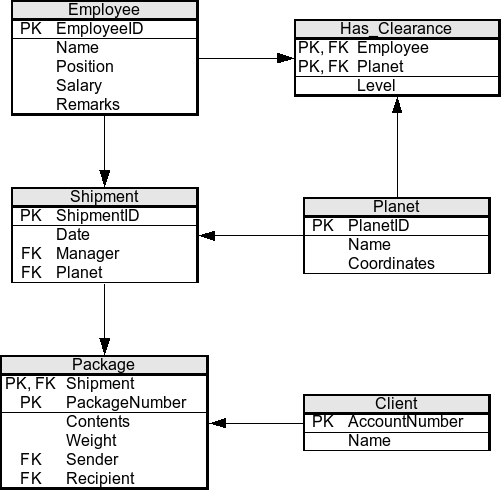
Document Model
This model shines when the data is self-contained and highly volatile. It also solves the problem I’ve mentioned above, as the format of the data is more closely (in some cases even directly) mapped to objects in the application. It is often represented as a JSON:
[ { "id": 1, "name": "Leanne Graham", "username": "Bret", "email": "[email protected]", "address": { "street": "Kulas Light", "suite": "Apt. 556", "city": "Gwenborough", "zipcode": "92998-3874" }, "phone": "1-770-736-8031 x56442", "website": "hildegard.org", "company": { "name": "Romaguera-Crona", "catchPhrase": "Multi-layered client-server neural-net", "bs": "harness real-time e-markets" } } ]
Such approach provides better locality than relational model. If you were to display user profile in a relational database, you would have to query quite a bit of tables or perform a sloppy multi-join. The document model on the other hand allows you to fetch all information for a user using a single query as all the data is in one place.
Of course, it’s not perfect either. Most document databases don’t support joins at all. Say you wanted to extract company information to a separate document. In such case when fetching user data, you’d have to manually query for the company and join the data together. Most probably you would do so in application layer, which may slow things down a bit.
Network model
We have to make one last stop before we dive into graph databases. Network model was a direct competitor for relational databases back in the 1970s. This approach differs from a relational one in that it stores the links between records not with foreign keys, but more like pointers in C. Because of that the only way to access a record in the database is to follow the links of a root node.
Network model databases are based on hierarchical data model, which means the data is stored more or less like a tree. Due to that fact, you can’t just link any nodes you want. Each child must have exactly one parent, and each parent can have multiple children. These databases also use fixed records, meaning you can’t add arbitrary properties.
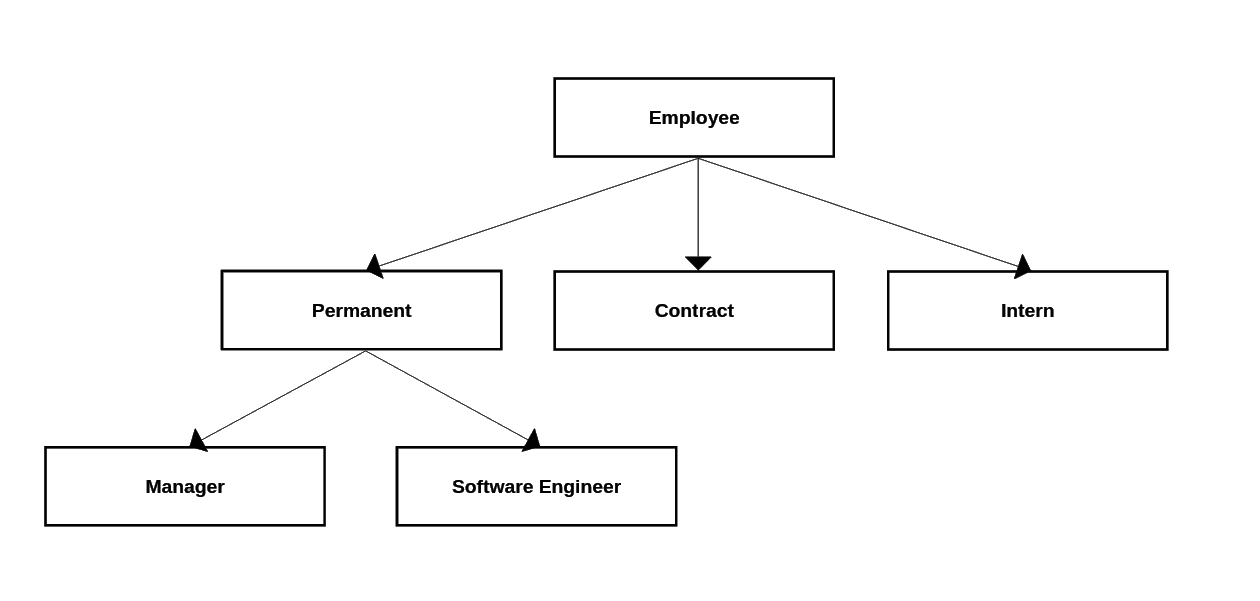 It works much like
It works much like get/findoperations in a linked list, where you start from the head of the list and follow the next item until you find what you’re looking for. But that’s only the simplest case. In real world there are lots of many-to-many relations which make things more challenging, as there are many ways to create a path between two points on a graph.
Graph model
Last but not least, there’s a graph model. If your data is highly interconnected, then that’s the data model you will want to look into. It’s the reason why lots of big companies started employing this model. You’re already making use of the benefits of graphs if you’re using Facebook, Google, Amazon, Twitter or Instagram. They use them to perform complex analytics on how users interact with other users, item auctions or simple web searches, etc.
While network and graph sound very much alike, these models aren’t the same. Graphs are much more flexible in a sense that they allow for arbitrary properties/relationships.

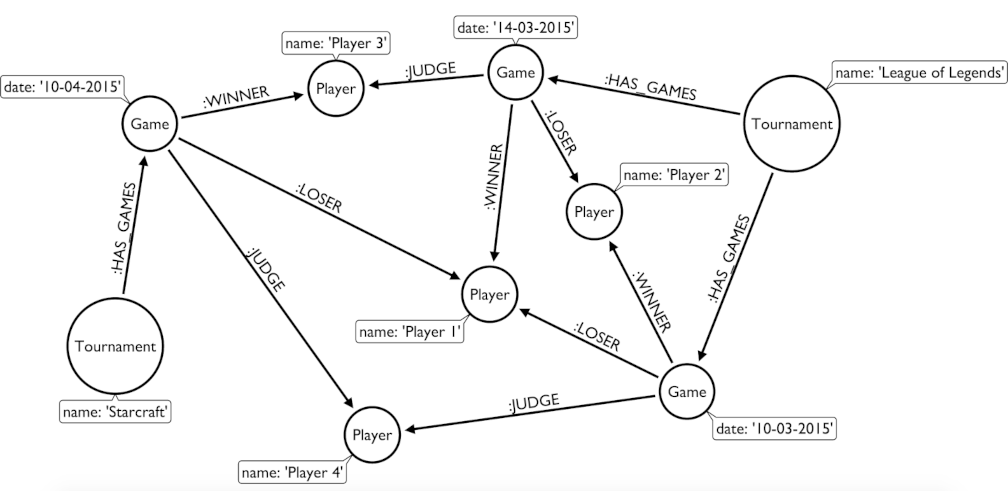
Graph structure
Each graph consists of:
- Graph: An object that contains vertices and edges.
- Element: An object that can have any number of key/value pairs associated with it (i.e. properties)
- Vertex: An object that has incoming and outgoing edges.
- Edge: An object that has a tail and head vertex.
Graph models
- Property Graph Model – it boils down to the fact that all elements have an identifier, properties and a label. Additionally, every vertex has a set of outgoing and incoming edges and each edge has a tail and head vertex. There’s a bit more about it in here.
- Triple-store – every information is being stored as a very simple statement that consists of three parts: subject, predicate and object, e.g.
John,likes,LucyorJohn,age,24
Query languages
- Gremlin – functional language designed specifically for graph databases, it’s a de facto standard in the graph world that many vendors utilize and contribute to.
graph.V().has('movie','name','Die Hard')
.inE('rated')
.values('stars')
.mean()- Cypher – it employs an ascii-art technique to represent graph information in queries. It was created for Neo4j database and at the same time it’s being used pretty much solely by it.
MATCH (:Actor {name: 'Nicole Kidman'})-[:ACTED_IN]->(movie:Movie)
WHERE movie.year < 2015
RETURN movie- GraphQL – it’s a less obvious choice, but some databases use a modified version of GraphQL too. The language itself is rather simple but simultaneously it fits the graph model well. The sample below is a GraphQL+- snippet which was created for Dgraph.
{
brCharacters(func: eq(name@en, "Blade Runner")) {
name@en
initial_release_date
starring {
performance.actor {
name@en # actor name
}
performance.character {
name@en # character name
}
}
}
}- SQL – it is possible to query graph data with the use of SQL, there are some quirks though. There could be some cases in which you need to follow an edge a number of times. While it’s doable in SQL, the query will be much longer and more complicated. However, there is OrientDB which extends the SQL in order to make it easier for developers to write queries.
SELECT name, OUT("Friend").name AS friendName FROM PersonGraph use cases
As already mentioned, the graph model excels when the data has lots of many-to-many relationships, therefore all of the following can be considered valid use cases for graphs:
- social media – e.g. friend network on Facebook, user circles on Google Plus
- network architecture – map of all network layers (how applications, servers, datacenters, routers etc. relate to each other)
- web graphs – how websites reference each other
- collaboration networks – github projects and contributors
- communication networks – messaging applications
- road networks – graph that shows the possibilities of travelling between places
- fraud detection – detecting suspicious actions
- chemistry – how compounds react with each other
- biology – DNA-trait relations (which gene causes what)
- medicine – chemicals and side effects
Comparison of popular graph databases
(scroll the table to the right)
| JanusGraph | OrientDB | Dgraph | ArangoDB | Neo4j Community | Neo4j Enterprise | |
|---|---|---|---|---|---|---|
| StackOverflow questions | 619 | 2,665 | 82 | 1,682 | 19,757 | |
| Initial release | 2017 | 2010 | 2016 | 2011 | 2007 | |
| Last release date (as of 09/2020) | 05/2020 | 09/2020 | 07/2020 | 10/2020 | 07/2020 | |
| Built in | Java | Java | Go | C++ | Java | |
| Architecture | sharding built-in, scalability handled by storage backend | sharded (with some limitations) and distributed, multi master replication | sharding per predicate, replicas have full dataset unless it’s too big, otherwise replica groups are created | many deployment modes (single instance / master slave / active failover / cluster) | not distributed (only scalable vertically) | a few core (write) servers + many replica (read) servers, sharded |
| Storage engine | depends on storage backend | plocal | Badger | RocksDB | custom solution | |
| APIs | WS/HTTP, many popular PL | Binary, REST, many popular PL | JSON/protobuf over gRPC/HTTP | REST, Java/JS/PHP/Go drivers (+ more from community, e.g. python, .Net) | BOLT, REST, many popular PL | |
| Query language | Gremlin | SQL | GraphQL or GraphQL+- | AQL | Cypher | |
| License | Apache 2.0 | Apache 2.0 | Apache 2.0 | Apache 2.0 | GPLv3 | GPLv3 / commercial |
| Geo search | built-in | built-in | built-in | built-in | external | |
| Full-text search | pluggable, external (lucene, SOLR, ES) | built-in | built-in | built-in | external | |
| Company behind | community-driven (developed by e.g. IBM, Google, Hortonworks, Amazon) | SAP | Dgraph Labs | ArangoDB | Neo Technology | |
| Price (annually) | free | free (enterprise: hidden, approx. $6k – $10k) | free (enterprise: hidden) | free (enterprise: hidden) | free | hidden, approx. $30k – $200k |
| Spring Data support | Kind of (there’s a plugin but it’s bugged) | No | No | Yes | Yes | |
| Detailed summary | https://docs.janusgraph.org/ | https://orientdb.com/docs/3.0.x/misc/Overview.html | https://dgraph.io/docs/faq/# | https://www.arangodb.com/why-arangodb/arangodb-vs-neo4j/ | https://neo4j.com/product/ |
Summary
The thing about graphs is that they are ideal for modern data, especially for Big Data. They just fit perfectly the direction in which the IT goes, that is the one of ever increasing data volume and complexity. I sincerely believe that now is the best time to employ graph databases because of how much interest they gain. And it doesn’t seem like they will vanish in future, I’m sure it’s quite the opposite.



